
古月居《Ros 入门21讲》第 10 ~ 16 讲踩坑记录和学习笔记
一、话题模型 —— 发布订阅
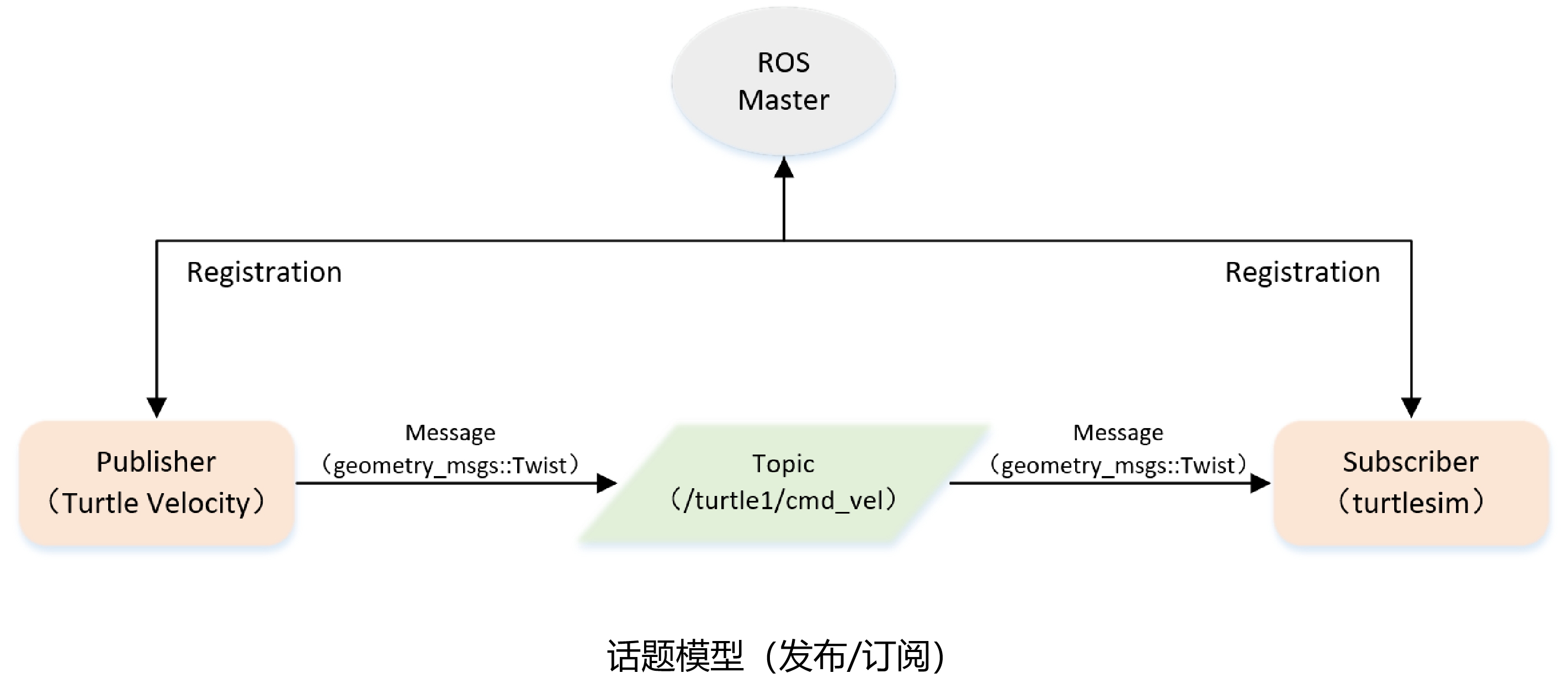
1.1 发布者 Publisher 的编程实现
首先创建功能包,在 catkin_ws/src 目录下打开终端执行:
1 | catkin_create_pkg learning_topic roscpp rospy std_msgs geometry_msgs turtlesim |
创建功能包 learning_topic 并指定其依赖项 roscpp rospy std_msgs geometry_msgs turtlesim。
下面编写代码逻辑:
- 初始化节点并创建句柄 (句柄用于处理节点的资源)
- 通过句柄向 ROS Master 注册节点信息,包括发布的话题名和话题中的消息类型
- 创建消息数据,指定循环发布的频率
- 循环发布消息
在功能包的 src 目录下创建 velocity_publisher.cpp 文件,编写如下代码:
1 | /** |
handle.advertise() 函数用于在 ros master 注册话题名和话题数据类型,返回 Publisher 对象。通过调用此对象的 publish 函数,可以在其对应的话题上发布消息。
然后配置编译规则:在 CMakeLists.txt 文件中找到 Build 部分的配置,添加两行代码:
1 | add_executable(velocity_publisher src/velocity_publisher.cpp) |
解析:
add_executable(目标文件名,src1,src2,src3…); 用于根据源文件生成目标可执行文件
target_link_libraries(目标文件名,${catkin_LIBRARIES}); 用于链接目标可执行文件和库文件
再在 catkin_ws 路径下通过 catkin_make 命令编译文件,输出的目标可执行文件路径在 catkin_ws/devel/lib/learning_topic 下,是一个名为 velocity_publisher 的可执行文件。
运行前先配置环境变量:打开主文件夹键入 CTRL + H 显示被隐藏的文件,找到 .bashrc 并打开,在最后一行添加环境变量的路径 source /home/zhenyu/catkin_ws/devel/setup.bash 保存关闭即可。或者通过输入命令行完成环境变量配置:
1 | source devel/setup.bash |
用命令行输入的环境变量配置只是临时的,写入 .bashrc 文件的话可以永久设置环境变量,之后在任何目录都可以运行 rosrun 命令。
以上工作都完成后,打开三个命令行窗口,分别输入:
1 | roscore |
就可以看到小海龟按照 cpp 文件的命令开始运动,并且终端会打印日志信息。按下 CTRL + C 即可停止发布。如果是 Python 程序的话,可以省略上面的编译过程,直接 rosrun 即可。
1.2 订阅者 Subscriber 的编程实现
代码逻辑:
- 初始化 Ros 节点
- 创建句柄,注册节点信息,订阅需要的话题
- 循环等待话题消息
- 在回调函数中完成消息处理
同样,在功能包的 src 目录创建 pose_subscriber.cpp 文件,编写代码如下:
1 | /** |
编译和运行与发布者相似,不做赘述。此程序的功能是不断在终端输出小海龟所处位置坐标。
1.3 话题消息的定义与使用
1.3.1 自定义话题消息
在 learning_topic 文件夹中添加 msg 文件夹,并在其中创建 Person.msg 文件。编写以下代码:
1 | string name |
下面三行是程序中对’性别’的宏定义,每行开头的 ‘string’ 和 ‘uint’ 会在编译的过程中,根据不同的编程语言动态地扩展成不同的数据类型。
然后在 package.xml 中添加能够动态生成程序的功能包依赖,需要引入一组 build_depend 和 exec_depend:
1 | <build_depend>message_generation</build_depend> |
最后在 CMakeLists.txt 添加编译选项并编译:
- find_package( …… message_generation):对应于上一步添加的功能包 message_generation
- 在标注有 ‘Declare ROS messages, services and actions’ 的模块下添加:前一条语句是将 Person.msg 文件作为接口进行编译,后一条语句是配置在编译这个 .msg 文件的时候,需要依赖 Ros 库 std_msgs,因为其中定义了上面提到的 string、uint8 等数据类型
1
2add_message_files(FILES Person.msg)
generate_messages(DEPENDENCIES std_msgs) - catkin_package(…… message_runtime):添加编译时的依赖,这里需要去掉注释的 # 号,并且在后面添上 message_runtime
- 在根目录下编译,成功后可以在 catkin_ws/devel/include/learning_topic 路径下看到 Person.h 文件,之后在 cpp 程序中会用作头文件引入。
1.3.2 使用自定义话题消息
发布者和订阅者的代码如下:
1 | /** |
1 | /** |
下面在 CMakeLists.txt 文件中的 build 模块添加编译规则,注意这里要多两行:
1 | add_executable(person_publisher src/person_publisher.cpp) |
回到工作空间根目录 catkin_ws 编译,完成后就可以开始调试:
首先运行 roscore,roscore 扮演者 “婚姻中介” 的角色,即为两个节点之间完成连接的建立;建立之后即便停止 roscore 也不会影响已经建立好连接的两个节点继续进行通信。
然后分别运行 Subscriber 和 Publisher:
1 | rosrun learning_topic person_subscriber |
可以看到两边都在打印信息,即使退出 roscore 也不受影响。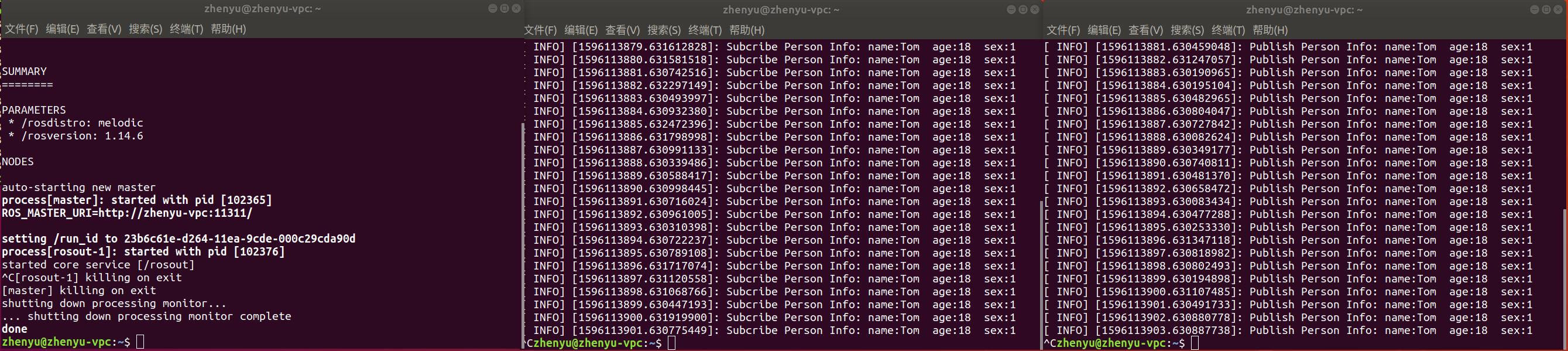
1.4 C++ 补充知识
1.4.1 命名空间和作用域操作符 ‘::’
命名空间 (namespace):为了防止变量名被重复定义,而将变量的定义放在一个特定的空间中。
例如小李和小韩都参与了一个文件管理系统的开发,它们都定义了一个全局变量 fp 用来指明当前打开的文件,将他们的代码整合在一起编译时,很明显编译器会提示 fp 重复定义(Redefinition)错误。这时就需要将他们定义的全局变量 fp 放在不同的命名空间中:
1 | // 命名空间里面可以包含变量、函数、类、typedef、#define 等,最后由 { } 包围。 |
作用域操作符 ‘::’ 就是用来读取指定作用域中的变量,如 Li::fp
如果使用作用域操作符觉得较繁琐,可以用命名空间的 using 声明,声明之后系统会默认在未指定命名空间的情况下,变量属于 using 声明中指定的命名空间:
1 | using Li::fp; |
using 也可以声明整个命名空间,声明后所有未指定命名空间的变量都默认是被声明的命名空间中的变量:
1 | using namespace Li; |
注意:
- 如果将命名空间的 using 声明放在函数内部,此声明仅在函数的作用域内有效,在大型项目中也推荐开发者这么做。如果将其声明在所有函数的外部,则此声明是全局有效的,但是在大型项目中容易引起混乱,增加了命名冲突的风险,故不建议这么做。
- 所有 using 声明语句都必须以分号作为结尾。
- 头文件中不应包含 using 声明,因为头文件中的代码会被拷贝到所有引用它的程序当中。
1.4.2 箭头运算符 ‘->’、引用和指针
箭头运算符的操作 = 解引用 + 成员访问,例:
1 | // 以下两个表达式作用相同 |
补充:
- ‘*’ 为解引用操作符 (对指针解引用会得到其所指对象),或用于定义指针类型的变量 (如 int *p)
- ‘&’ 为取地址操作符 (常用于指针类型变量初始化),或用于定义引用类型的变量 (如 int &r)
注意事项:
- 定义引用时,程序将引用与其初始值绑定在一起,而非将初始值拷贝给引用。因此引用必须初始化,而指针本身是个对象,可以不初始化 (但是建议初始化所有指针)。
- 引用相当于对象的别名但本身并非对象,故不能创建引用的引用。
- 引用一旦定义,就无法令其绑定到新的对象,而指针没有这些限制。
- 定义空指针的方法:int *p = nullptr(推荐) 或 0 或 NULL(尽量避免)。
- 不能将变量直接赋值给指针 (即便其值可能为0),需要加上取地址符 &。
- 除常量引用和 (15.3.2 类型转换与继承) 以外,引用类型和其绑定的数据类型须严格匹配,且不能与字面值或表达式的计算结果绑定在一起。
- 除常量指针和 (15.3.2 类型转换与继承) 以外,指针类型和其指向的数据类型须严格匹配。
1.4.3 值传递、指针传递和引用传递
- 值传递:形参是实参的拷贝,其变化不影响实参;
- 指针传递:形参是实参的拷贝,但与实参指向同一对象;
- 引用传递:形参是实参的别名,对形参的操作就是对实参的操作;
在 C++ 当中,建议使用引用传递代替指针传递。
为什么要用引用传递:
- 拷贝大的容器类型或类类型的对象比较低效
- 有的类类型不支持拷贝操作
- 可以通过引用形参返回额外信息 (《C++ Primer 第五版》P189)
如果想要避免拷贝且函数无须改变引用形参的值,最好将其声明为常量引用
1.4.4 常量引用
类比于常量对象不能被修改,常量引用也不能通过引用修改对象的值。
1 | int i = 2048; |
C++ 允许给一个常量引用绑定非常量的对象,但不允许给一个非常量的引用绑定一个常量对象。
1 | int i = 2048; |
给一个常量引用绑定非常量的对象时,编译器自动做了如下操作:
1 | // 当我们做如下操作 |
因此,虽然我们不能通过常量引用修改其所绑定的对象的值,但当这个对象是一个非常量的时候,C++ 允许我们通过其他方式改变它的值。
1 |
|
在上面的例子中,常量引用和其绑定的对象 i 都是 int 型的,可以看到 r1 始终绑定在变量 i 上,两者同步变化。
如果常量引用和其绑定的对象类型不同,则 r1 不会再绑定在 i 上。例如:
1 |
|
本例说明,当常量引用和其绑定的对象类型不同时,两者并不能真正的“绑定”在一起。
小结:常量引用只是引用“自以为”指向了常量,所以自觉地不去改变所指对象的值。常量引用在编译时会带上生成零时常量并绑定的逻辑,在引用与其对象的数据类型相同时,两者会同步变化;数据类型不同时,两者实际上没有真正绑定在一起。
1.4.5 回到之前的代码
1 | // 接收到订阅的消息后,会进入消息回调函数 |
这里从函数体中的箭头符号和形参的表示可以看出,msg 应该是一个指针的常量引用,这个指针指向发出的消息这一对象,所以用箭头函数先解引用,再获取该对象的成员。具体的 ConstPtr 的含义我还不清楚,网上查到的解释也还没看懂,先把它放到了参考文献当中。
二、服务模型 —— 服务器/客户端
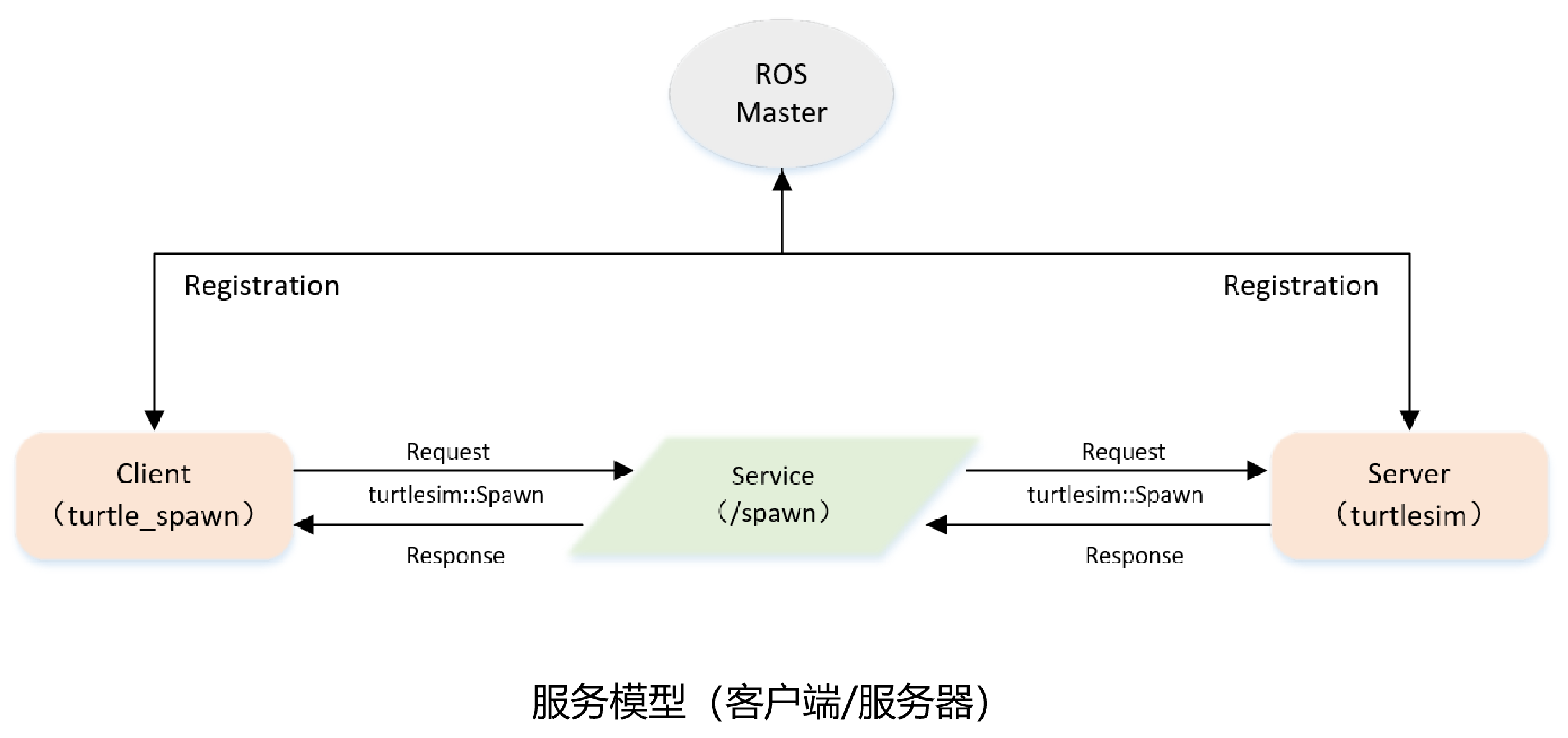
2.1 客户端 Client 的编程实现
- 初始化ROS节点并创建句柄;
- 检查所需服务是否存在,若存在则继续创建一个Client实例,否则原地等待;
- 初始化请求数据,发布服务请求数据并原地等待结果返回;
- 处理 Server 返回的的应答结果
步骤与前面的类似,这里不作详细阐述:
- 根目录创建功能包
1
2cd ~/catkin_ws/src
catkin_create_pkg learning_service roscpp rospy std_msgs geometry_msgs turtlesim - 功能包的 src 目录下创建并编写程序
turtle_spawn.cpp 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37/**
* 该例程将请求/spawn服务,服务数据类型turtlesim::Spawn
*/
int main(int argc, char** argv)
{
// 初始化ROS节点
ros::init(argc, argv, "turtle_spawn");
// 创建节点句柄
ros::NodeHandle node;
// 发现/spawn服务后,创建一个服务客户端,连接名为/spawn的service
ros::service::waitForService("/spawn"); // 阻塞,等检查到服务'/spawn'存在才会执行下一条
ros::ServiceClient add_turtle = node.serviceClient<turtlesim::Spawn>("/spawn");
// 初始化turtlesim::Spawn的请求数据
turtlesim::Spawn srv;
srv.request.x = 2.0;
srv.request.y = 2.0;
srv.request.name = "turtle2";
// 请求服务调用
ROS_INFO("Call service to spwan turtle[x:%0.6f, y:%0.6f, name:%s]",
srv.request.x, srv.request.y, srv.request.name.c_str());
add_turtle.call(srv); // 阻塞,等收到了服务器返回的结果才会执行下一条
// 显示服务调用结果
ROS_INFO("Spwan turtle successfully [name:%s]", srv.response.name.c_str());
return 0;
}; - 在 CMakeLists.txt 文件的 build 模块设置需要编译的代码及其对应可执行文件、设置链接库
1
2add_executable(turtle_spawn src/turtle_spawn.cpp)
target_link_libraries(turtle_spawn ${catkin_LIBRARIES}) - catkin_ws 根目录 catkin_make 编译
- 打开三个终端,分别依次运行:看到第二支小海龟出现,说明运行成功。
1
2
3roscore
rosrun turtlesim turtlesim_node
rosrun learning_service turtle_spawn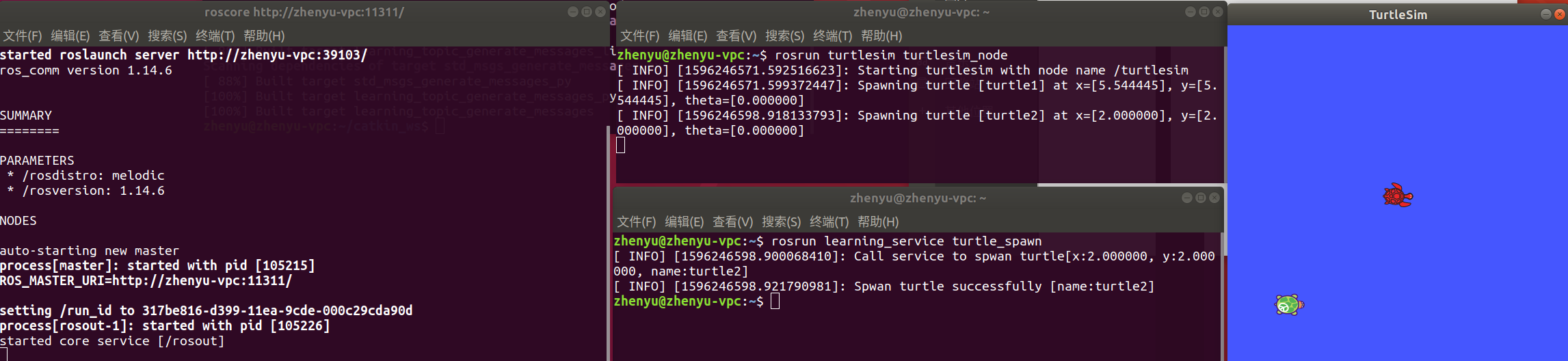
2.2 服务端 Server 的编程实现
- 初始化ROS节点并创建句柄;
- 创建Server实例;
- 循环等待服务请求,进入回调函数;
- 在回调函数中完成服务功能的处理,并反馈应答数据
还是在上一个功能包的 src 目录下,编写程序:
1 | /** |
同样配置 CMakeLists.txt,如下:
1 | add_executable(turtle_command_server src/turtle_command_server.cpp) |
最后,编译并运行,注意最后一段命令在 rosservice call /turtle_command 后面按两下 Tab 键可以自动补全。
1 | catkin_make |
看到如下结果,说明运行成功。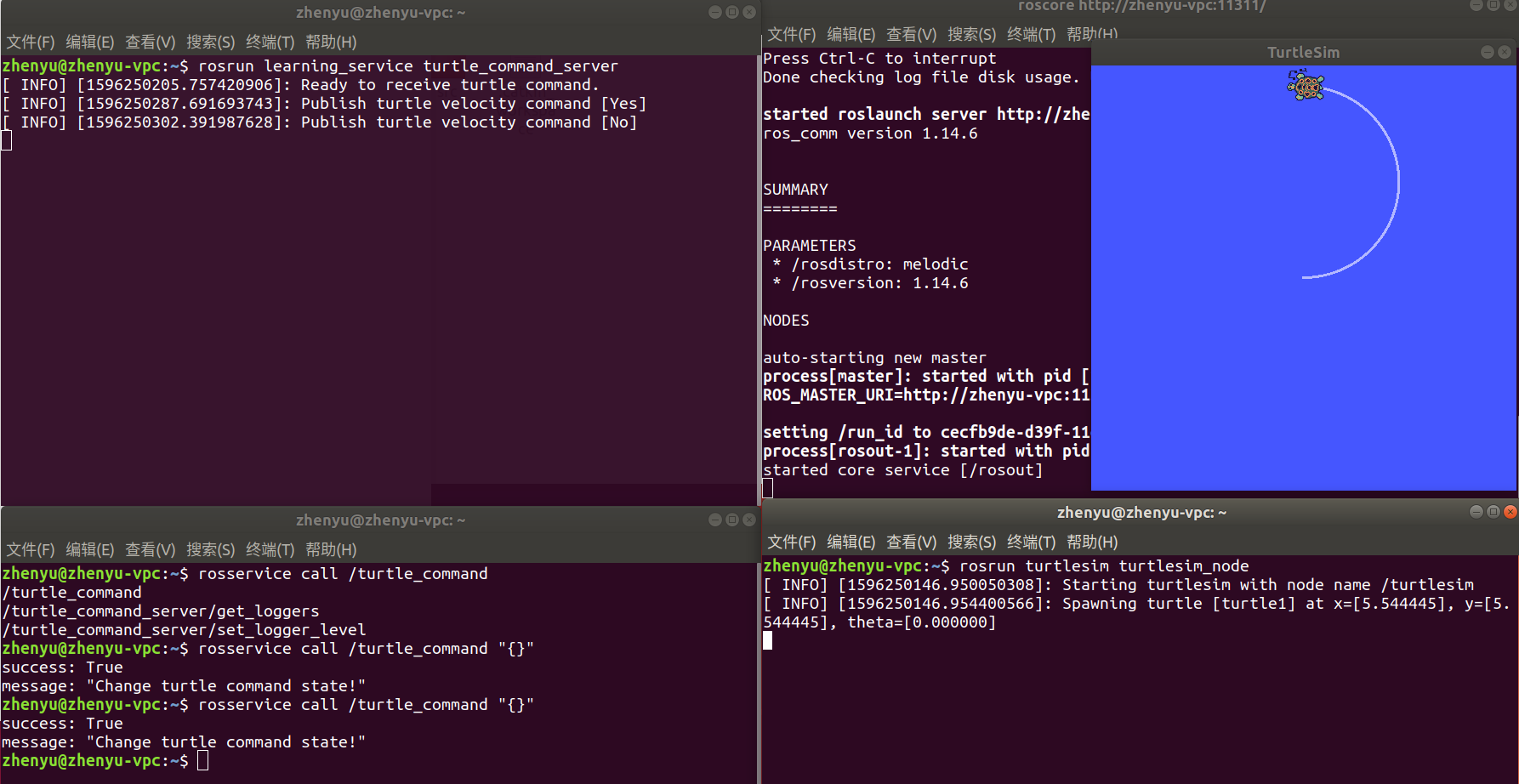
2.3 服务数据的定义与使用
2.3.1 自定义服务数据
与自定义话题消息类似,首先在 learning_service 文件夹中创建 srv 文件夹,并在其中创建 Person.srv 文件,在文件中写入以下内容:
1 | string name |
要注意分界线 --- 的上面是要通过 Client 发给 Server 的数据类型,分界线下面是 Server 返回的 response 的数据类型。
同样,在 package.xml 文件和 CMakeLists.txt 文件中分别添加功能包依赖和编译选项,如下:
1 | <build_depend>message_generation</build_depend> |
1 | find_package( …… message_generation) |
最后,在根目录 catkin_make 编译生成相关头文件。编译完成后,在路径 catkin_ws/devel/include/learning_service 下可以看到三个文件:Person.h、PersonRequest.h 和 PersonResponse.h。
到这里服务数据就创建完成了,下面通过命令看一下这个数据类型是否能被展示出来:
1 | rossrv show learning_service/Person |
终端输出:
1 | uint8 unknown=0 |
说明服务数据定义成功。
2.3.2 使用自定义服务数据
在 catkin_ws/src/learning_service/src 路径下创建服务端和客户端的 cpp 文件,如下:
1 | /** |
1 | /** |
注:这里头文件只需要引入总体的头文件 Person.h,他已经包含了 request 和 response。
下面在 CMakeLists.txt 中添加编译规则 (可执行文件 + 链接 + 依赖),注意要多加两行代码来动态生成程序的功能包依赖
1 | add_executable(person_server src/person_server.cpp) |
根目录编译,开三个终端分别执行以下命令:
1 | roscore |
注意:在每次运行新的程序之前,建议关掉 roscore 重开,避免和新的参数和里面存的旧参数冲突。运行结果如下: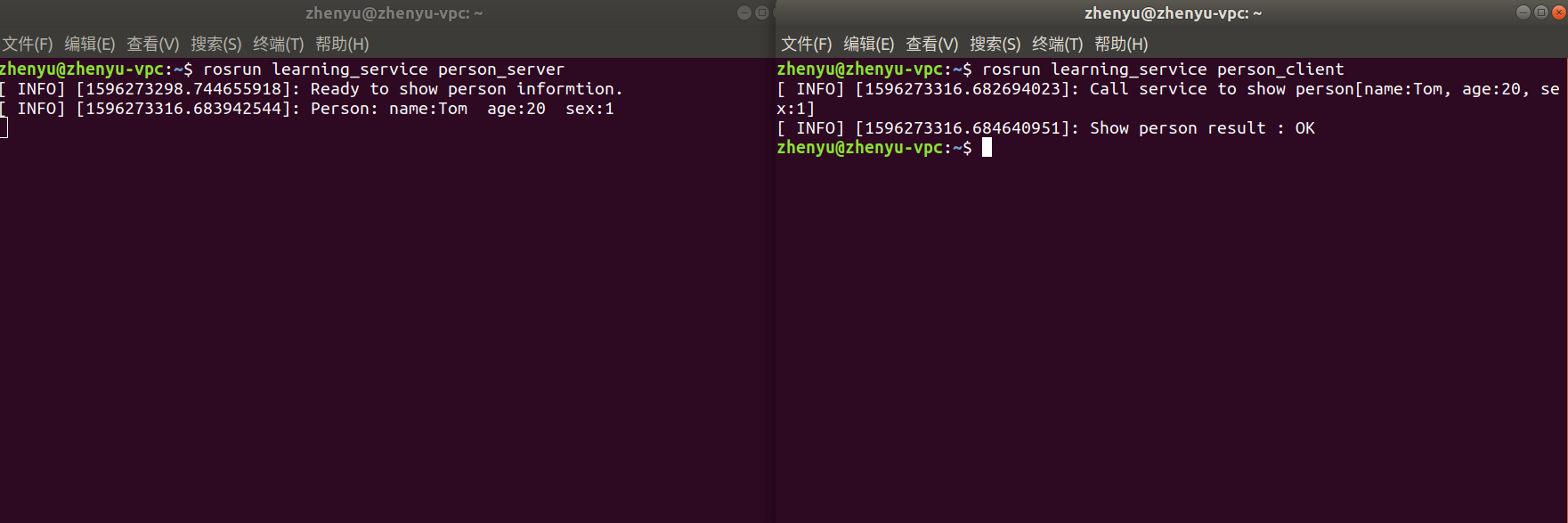
2.4 补充知识
2.4.1 ros::spin() 和 ros::spinOnce() 函数
首先梳理一下订阅者/服务器接收和处理消息的流程:
当消息被发送到订阅者/服务器 (以下简称订阅器) 时,订阅器会将消息所包含的 data 作为实参传递给回调函数,但回调函数并不会立即执行,而是像排队一样被放进一个回调函数的队列中。所以当发布器不断发送 data 给订阅器时,就会不断有相应的回调函数进入队列中,它们函数名一样,只是实参不一样。
那这些回调函数什么时候执行呢?这就是 ros::spin() 和 ros::spinOnce() 的事了。这两个函数负责检查回调函数的队列,如果里面有未执行的回调函数就将其执行。那这两个函数有什么区别呢?两者区别在于 ros::spin() 调用后不会再返回,相当于它在自己的函数里面死循环了。只要队列里面有回调函数在,它就会马上去执行回调函数。如果没有的话,它就会阻塞,不会占用CPU。而后者在调用后还可以继续执行之后的程序,但只调用一次,如果要不断检测并执行回调函数,就需要将这条语句放在一个循环当中。
这两个函数使用的优劣是?
- ros::spin() 函数用起来比较简单,一般都在主程序的最后,加入该语句就可。但是这条语句后面的语句就都不会被执行,所以使用的场景有限 (比如不能在循环中使用);
- ros::spinOnce() 的用法相对来说很灵活,但往往需要考虑调用消息的时机、调用频率、以及消息池的大小,这些都要根据现实情况协调好,不然会造成数据丢包或者延迟的错误。因为如果发布器发送数据的速度太快,spinOnce() 函数调用的频率太少,就会导致队列溢出,一些回调函数就会被挤掉,导致没被执行到。
综上,ros::spin() 和 ros::spinOnce() 函数是订阅器当中必须要带上的语句,否则订阅器是永远都处理不了另一边发出的数据或消息的。至于这两个函数的选择,需要根据具体的情况而定。我在参考文献里面加了相关的链接 (标了粗体),里面有处理 spinOnce() 考虑调用频率、消息池大小的例子,但因为我没有实际检验,所以不放在正文当中。之后可以参照他的例程做实验或者补充。
三、参数的使用与编程方法
什么是参数? —— 参数相当于“全局字典” (说全局变量不准确,因为它只适用于存储静态的、非二进制的配置参数)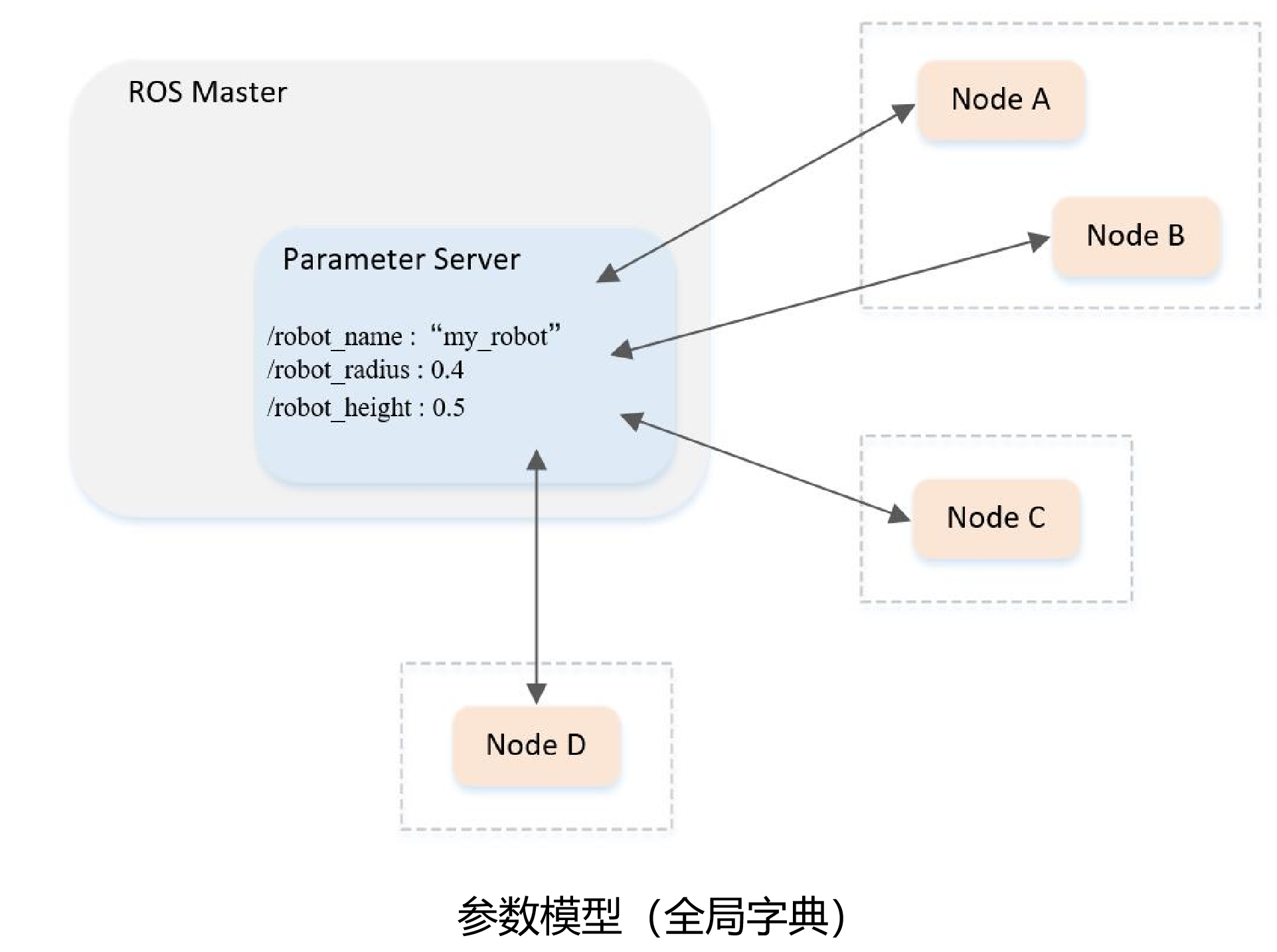
创建功能包:
1 | cd ~/catkin_ws/src |
3.1 参数命令行使用
| 命令 | 功能 |
|---|---|
| rosparam list | 列出当前所有参数 |
| rosparam get param_key | 显示某个参数值 |
| rosparam set param_key param_value | 设置某个参数值 |
| rosparam dump file_name | 保存参数到 .yaml 文件 |
| rosparam load file_name | 从文件读取参数 |
| rosparam delete param_key | 删除参数 |
注意:设置参数值后,新的参数不会立即生效,需要调用一个服务。比如修改小海龟运动的背景颜色,就需要再调用这条命令:
1 | // 注:这条命令本身的作用是清理乌龟的运动痕迹,这里只是利用了它在清理痕迹的同时会重新载入背景参数的特性 |
3.2 在程序中操作参数
在功能包的 src 文件夹创建文件、编写代码:
1 | /** |
设置 CMakeLists.txt:
1 | add_executable(parameter_config src/parameter_config.cpp) |
编译、运行
1 | $ catkin_make |
看到小海龟的背景颜色改变,说明程序运行成功。
补充一句:在编译上面的程序时,我遇到了这样的问题: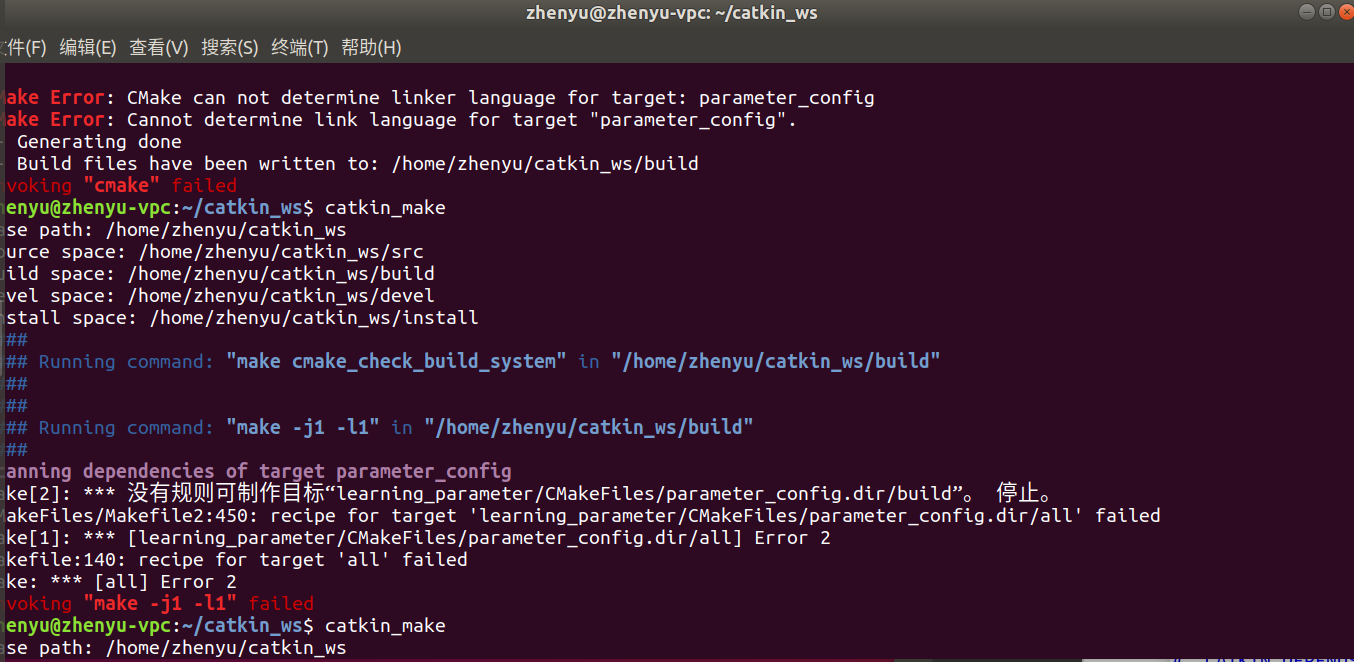
对于这个问题,我只是把 CMakeLists.txt 两行代码当中,每行后边多出来的空格删掉再编译就好了,很神奇,在这里也记录一下。
四、参考文献
传参时 const string& 相对 const string 有哪些优势?https://blog.csdn.net/xiongchengluo1129/article/details/79123487?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.channel_param&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.channel_param
C++ 中文网:http://c.biancheng.net/view/2192.html
c/c++值传递和引用传递:https://www.cnblogs.com/erzhu/p/4441482.html
关于回调函数中const std_msgs::String::ConstPtr& msg的一些解释:https://blog.csdn.net/kantswang/article/details/82947669
ros::spin() 和 ros::spinOnce() 函数:https://blog.csdn.net/liweibin1994/article/details/53084306
ros::spin() 和 ros::spinOnce() 区别及详解:https://www.cnblogs.com/liu-fa/p/5925381.html
《C++ Primer 第五版》电子工业出版社
在线编译工具:https://tool.lu/coderunner/